I’m freezing this blog and starting to post on my Substack instead. The authoring experience is much more convenient for me there. Please follow me there, and check out The Illustrated DeepSeek R-1 if you haven’t yet.
Can AI Image generation tools make re-imagined, higher-resolution versions of old video game graphics?
Over the last few days, I used AI image generation to reproduce one of my childhood nightmares. I wrestled with Stable Diffusion, Dall-E and Midjourney to see how these commercial AI generation tools can help retell an old visual story - the intro cinematic to an old video game (Nemesis 2 on the MSX). This post describes the process and my experience in using these models/services to retell a story in higher fidelity graphics.
Meet Dr. Venom
This fine-looking gentleman is the villain in a video game. Dr. Venom appears in the intro cinematic of Nemesis 2, a 1987 video game. This image, in particular, comes at a dramatic reveal in the cinematic.
Let’s update these graphics with visual generative AI tools and see how they compare and where each succeeds and fails.
Remaking Old Computer graphics with AI Image Generation
Here’s a side-by-side look at the panels from the original cinematic (left column) and the final ones generated by the AI tools (right column):
This figure does not show the final Dr. Venom graphic because I want you to witness it as I had, in the proper context and alongside the appropriate music. You can watch that here:
(V2 Nov 2022: Updated images for more precise description of forward diffusion. A few more images in this version)
AI image generation is the most recent AI capability blowing people’s minds (mine included). The ability to create striking visuals from text descriptions has a magical quality to it and points clearly to a shift in how humans create art. The release of Stable Diffusion is a clear milestone in this development because it made a high-performance model available to the masses (performance in terms of image quality, as well as speed and relatively low resource/memory requirements).
After experimenting with AI image generation, you may start to wonder how it works.
This is a gentle introduction to how Stable Diffusion works.
Stable Diffusion is versatile in that it can be used in a number of different ways. Let’s focus at first on image generation from text only (text2img). The image above shows an example text input and the resulting generated image (The actual complete prompt is here). Aside from text to image, another main way of using it is by making it alter images (so inputs are text + image).
A little less than a year ago, I joined the awesome Cohere team. The company trains massive language models (both GPT-like and BERT-like) and offers them as an API (which also supports finetuning). Its founders include Google Brain alums including co-authors of the original Transformers paper. It’s a fascinating role where I get to help companies and developers put these massive models to work solving real-world problems.
I love that I get to share some of the intuitions developers need to start problem-solving with these models. Even though I’ve been working very closely on pretrained Transformers for the past several years (for this blog and in developing Ecco), I’m enjoying the convenience of problem-solving with managed language models as it frees up the restrictions of model loading/deployment and memory/GPU management.
These are some of the articles I wrote and collaborated on with colleagues over the last few months:
This is a high-level intro to large language models to people who are new to them. It establishes the difference between generative (GPT-like) and representation (BERT-like) models and examples use cases for them.
This is one of the first articles I got to write. It's extracted from a much larger document that I wrote to explore some of the visual language to use in explaining the application of these models.
Massive GPT models open the door for a new way of programming. If you structure the input text in the right way, you can useful (and often fascinating) results for a lot of taasks (e.g. text classification, copy writing, summarization...etc).
This article visually demonstrates four principals to create prompts effectively.
This is a walkthrough of creating a simple summarization system. It links to a jupyter notebook which includes the code to start experimenting with text generation and summarization.
The end of this notebook shows an important idea I want to spend more time on in the future. That of how to rank/filter/select the best from amongst multiple generations.
Semantic search has to be one of the most exciting applications of sentence embedding models. This tutorials implements a "similar questions" functionality using sentence embeddings and a a vector search library.
The vector search library used here is Annoy from Spotify. There are a bunch of others out there. Faiss is used widely. I experiment with PyNNDescent as well.
Finetuning tends to lead to the best results language models can achieve. This article explains the intuitions around finetuning representation/sentence embedding models. I've added a couple more visuals to the Twitter thread.
This one is a little bit more technical. It explains the parameters you tweak to adjust a GPT's decoding strategy -- the method with which the system picks output tokens.
This is a walkthrough of one of the most common use cases of embedding models -- text classification. It is similar to A Visual Guide to Using BERT for the First Time, but uses Cohere's API.
You can find these and upcoming articles in the Cohere docs and notebooks repo. I have quite number of experiments and interesting workflows I’d love to be sharing in the coming weeks. So stay tuned!
Summary: The latest batch of language models can be much smaller yet achieve GPT-3 like performance by being able to query a database or search the web for information. A key indication is that building larger and larger models is not the only way to improve performance.
Video
The last few years saw the rise of Large Language Models (LLMs) – machine learning models that rapidly improve how machines process and generate language. Some of the highlights since 2017 include:
The original Transformer breaks previous performance records for machine translation.
BERT popularizes the pre-training then finetuning process, as well as Transformer-based contextualized word embeddings. It then rapidly starts to power Google Search and Bing Search.
GPT-2 demonstrates the machine’s ability to write as well as humans do.
First T5, then T0 push the boundaries of transfer learning (training a model on one task, and then having it do well on other adjacent tasks) and posing a lot of different tasks as text-to-text tasks.
GPT-3 showed that massive scaling of generative models can lead to shocking emergent applications (the industry continues to train larger models like Gopher, MT-NLG…etc).
For a while, it seemed like scaling larger and larger models is the main way to improve performance. Recent developments in the field, like DeepMind’s RETRO Transformer and OpenAI’s WebGPT, reverse this trend by showing that smaller generative language models can perform on par with massive models if we augment them with a way to search/query for information.
This article breaks down DeepMind’s RETRO (Retrieval-Enhanced TRansfOrmer) and how it works. The model performs on par with GPT-3 despite being 4% its size (7.5 billion parameters vs. 185 billion for GPT-3 Da Vinci).
RETRO incorporates information retrieved from a database to free its parameters from being an expensive store of facts and world knowledge.
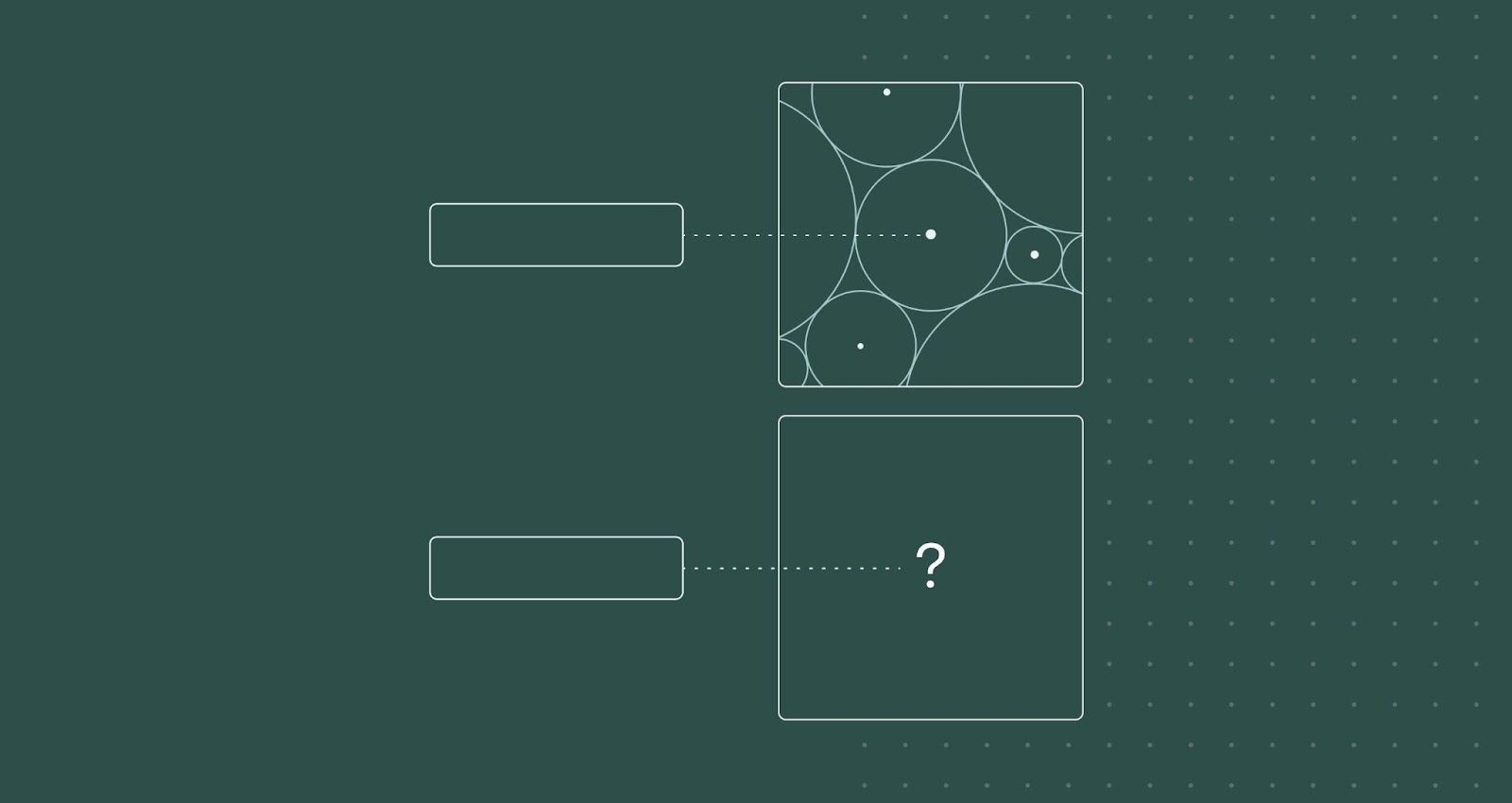
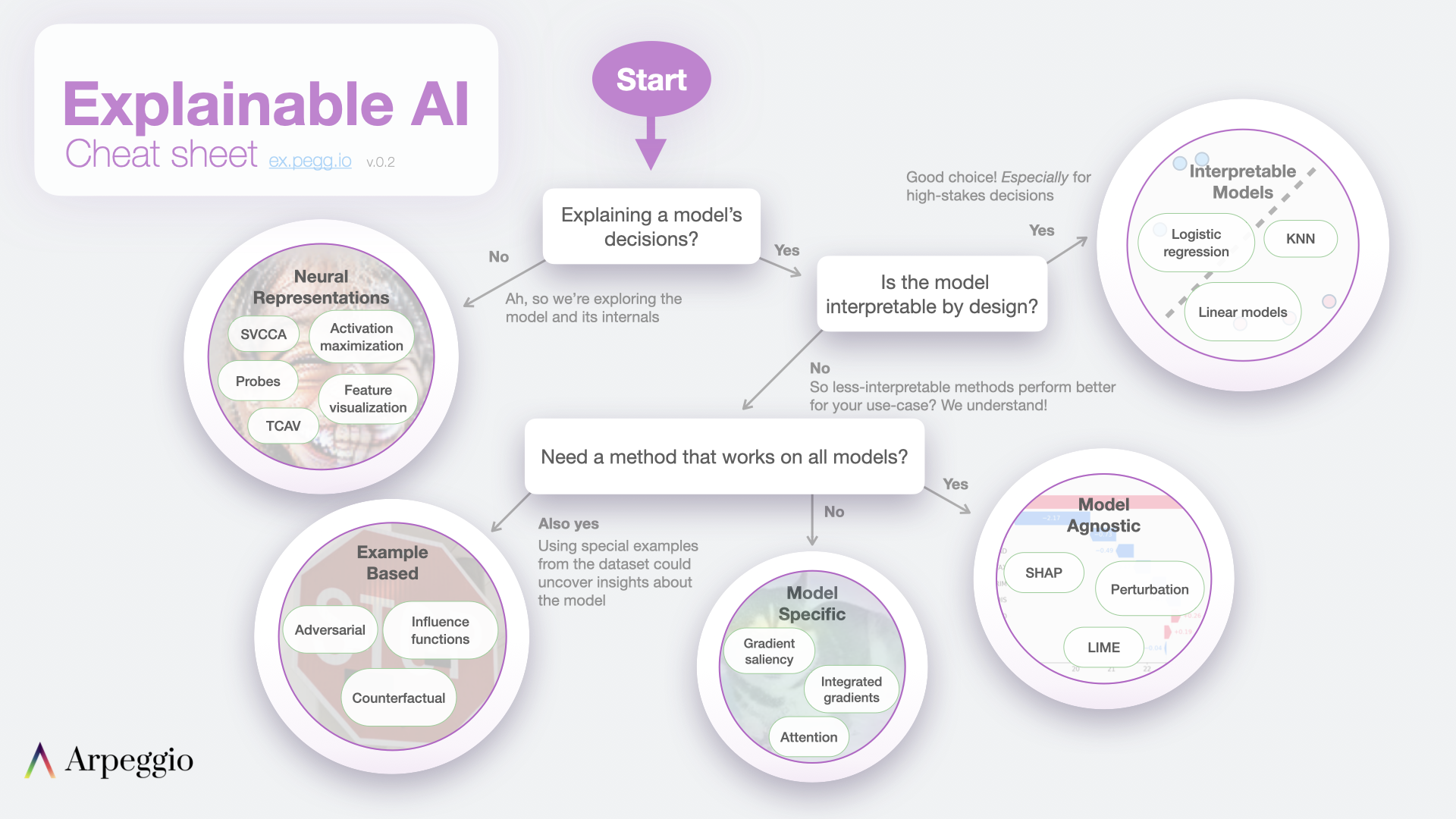
Introducing the Explainable AI Cheat Sheet, your high-level guide to the set of tools and methods that helps humans understand AI/ML models and their predictions.
By visualizing the hidden state between a model's layers, we can get some clues as to the model's "thought process".
Figure: Finding the words to say
After a language model generates a sentence, we can visualize a view of how the model came by each word (column). Each row is a model layer. The value and color indicate the ranking of the output token at that layer. The darker the color, the higher the ranking. Layer 0 is at the top. Layer 47 is at the bottom. Model:GPT2-XL
Part 2: Continuing the pursuit of making Transformer language models more transparent, this article showcases a collection of visualizations to uncover mechanics of language generation inside a pre-trained language model. These visualizations are all created using Ecco, the open-source package we're releasing
In the first part of this series, Interfaces for Explaining Transformer Language Models, we showcased interactive interfaces for input saliency and neuron activations. In this article, we will focus on the hidden state as it evolves from model layer to the next. By looking at the hidden states produced by every transformer decoder block, we aim to gleam information about how a language model arrived at a specific output token. This method is explored by Voita et al.. Nostalgebraist
presents compelling visual treatments showcasing the evolution of token rankings, logit scores, and softmax
probabilities for the evolving hidden state through the various layers of the model.
Interfaces for exploring transformer language models by looking at input saliency and neuron activation.
Explorable #1: Input saliency of a list of countries generated by a language model Tap or hover over the output tokens:
Explorable #2: Neuron activation analysis reveals four groups of neurons, each is associated with generating a certain type of token Tap or hover over the sparklines on the left to isolate a certain factor:
The Transformer architecture
has been powering a number of the recent advances in NLP. A breakdown of this architecture is provided here . Pre-trained language models based on the architecture,
in both its auto-regressive (models that use their own output as input to next time-steps and that process tokens from left-to-right, like GPT2)
and denoising (models trained by corrupting/masking the input and that process tokens bidirectionally, like BERT)
variants continue to push the envelope in various tasks in NLP and, more recently, in computer vision. Our understanding of why these models work so well, however, still lags behind these developments.
This exposition series continues the pursuit to interpret
and visualize
the inner-workings of transformer-based language models.
We illustrate how some key interpretability methods apply to transformer-based language models. This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well.
This is the first article in the series. In it, we present explorables and visualizations aiding the intuition of:
Input Saliency methods that score input tokens importance to generating a token.
Neuron Activations and how individual and groups of model neurons spike in response to
inputs and to produce outputs.
The next article addresses Hidden State Evolution across the layers of the model and what it may tell us about each layer's role.
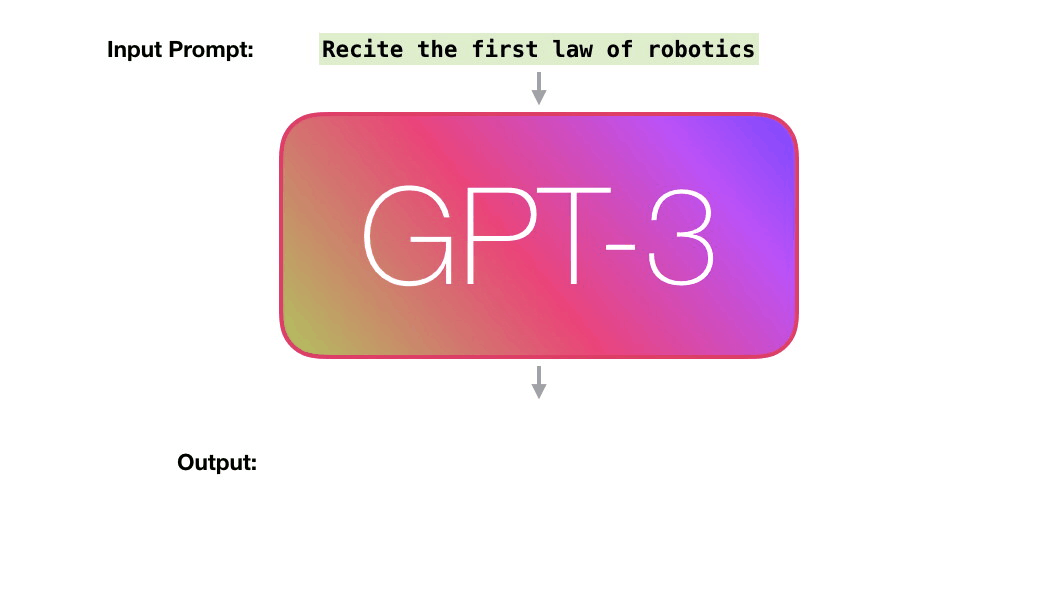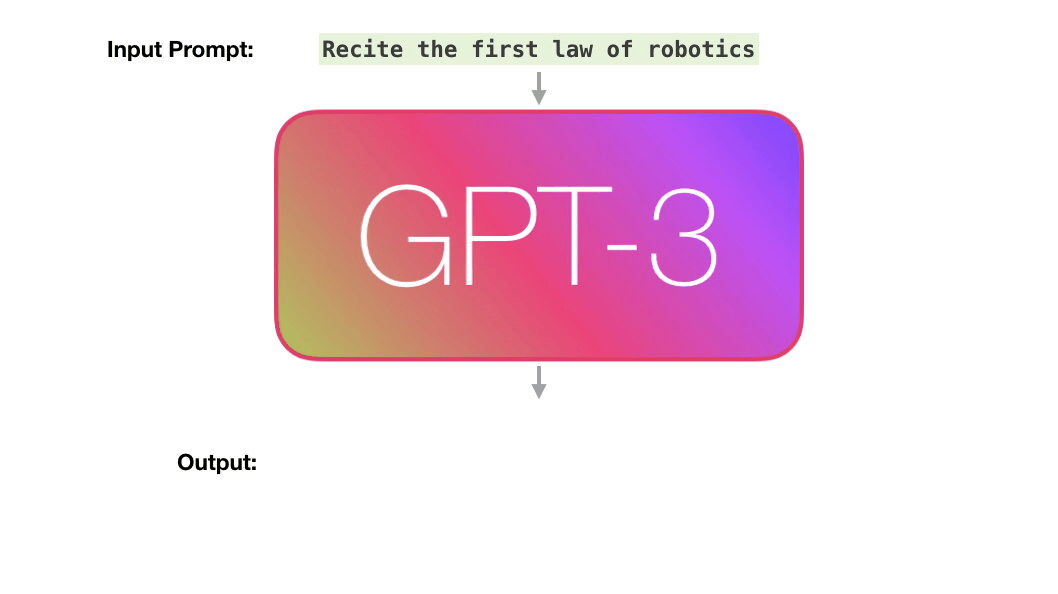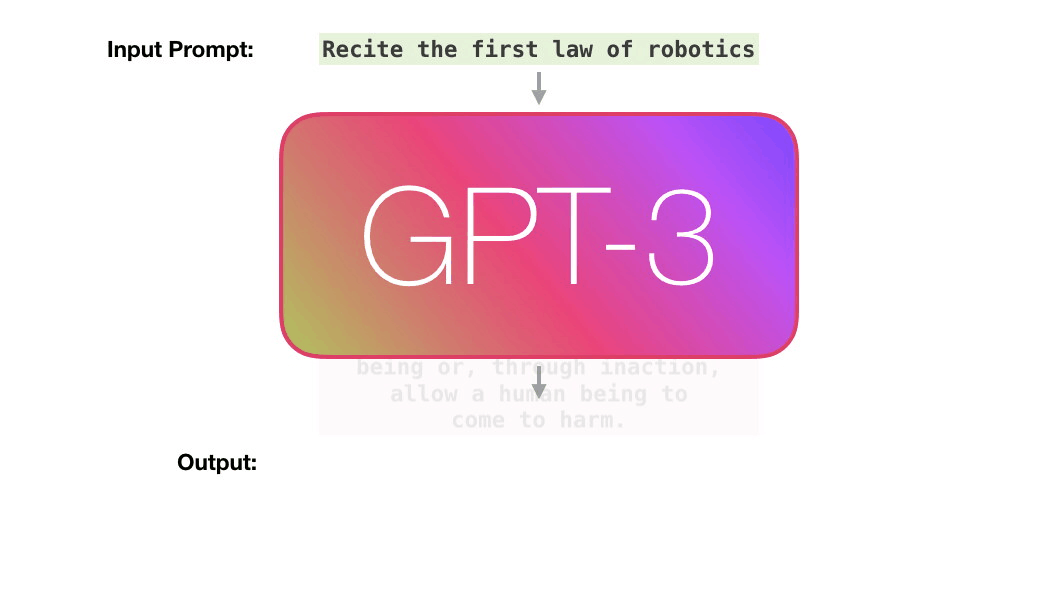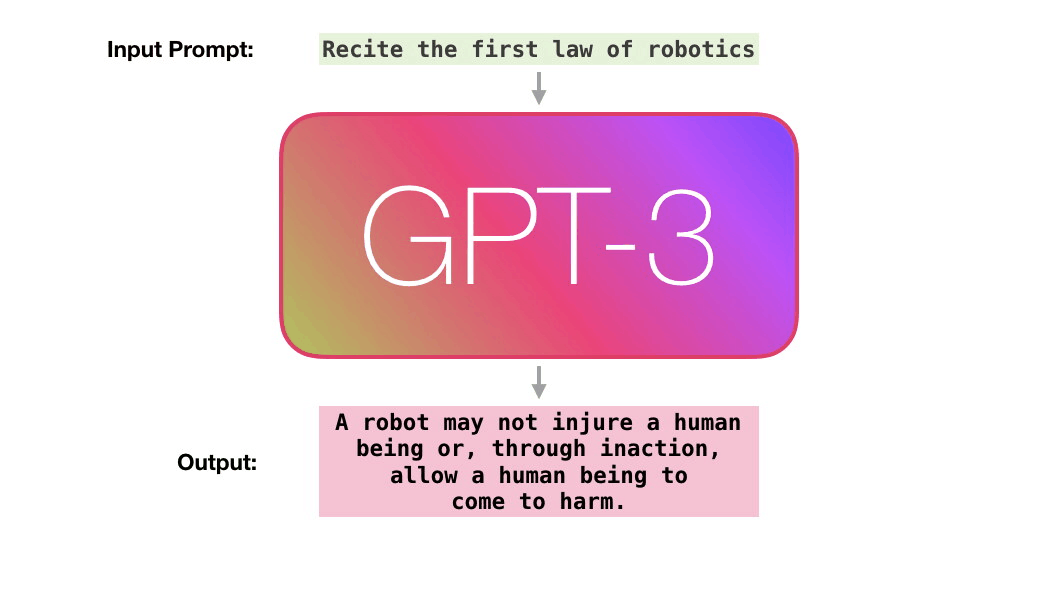
The tech world is abuzz with GPT3 hype. Massive language models (like GPT3) are starting to surprise us with their abilities. While not yet completely reliable for most businesses to put in front of their customers, these models are showing sparks of cleverness that are sure to accelerate the march of automation and the possibilities of intelligent computer systems. Let’s remove the aura of mystery around GPT3 and learn how it’s trained and how it works.
A trained language model generates text.
We can optionally pass it some text as input, which influences its output.
The output is generated from what the model “learned” during its training period where it scanned vast amounts of text.
QCon is a global software conference for software engineers, architects, and team leaders, with over 1,600 attendees in London. All speakers have a software background.
Progress has been rapidly accelerating in machine learning models that process language over the last couple of years. This progress has left the research lab and started powering some of the leading digital products. A great example of this is the recent announcement of how the BERT model is now a major force behind Google Search. Google believes this step (or progress in natural language understanding as applied in search) represents “the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search”.
This post is a simple tutorial for how to use a variant of BERT to classify sentences. This is an example that is basic enough as a first intro, yet advanced enough to showcase some of the key concepts involved.
This year, we saw a dazzling application of machine learning. The OpenAI GPT-2 exhibited impressive ability of writing coherent and passionate essays that exceed what we anticipated current language models are able to produce. The GPT-2 wasn’t a particularly novel architecture – it’s architecture is very similar to the decoder-only transformer. The GPT2 was, however, a very large, transformer-based language model trained on a massive dataset. In this post, we’ll look at the architecture that enabled the model to produce its results. We will go into the depths of its self-attention layer. And then we’ll look at applications for the decoder-only transformer beyond language modeling.
My goal here is to also supplement my earlier post, The Illustrated Transformer, with more visuals explaining the inner-workings of transformers, and how they’ve evolved since the original paper. My hope is that this visual language will hopefully make it easier to explain later Transformer-based models as their inner-workings continue to evolve.
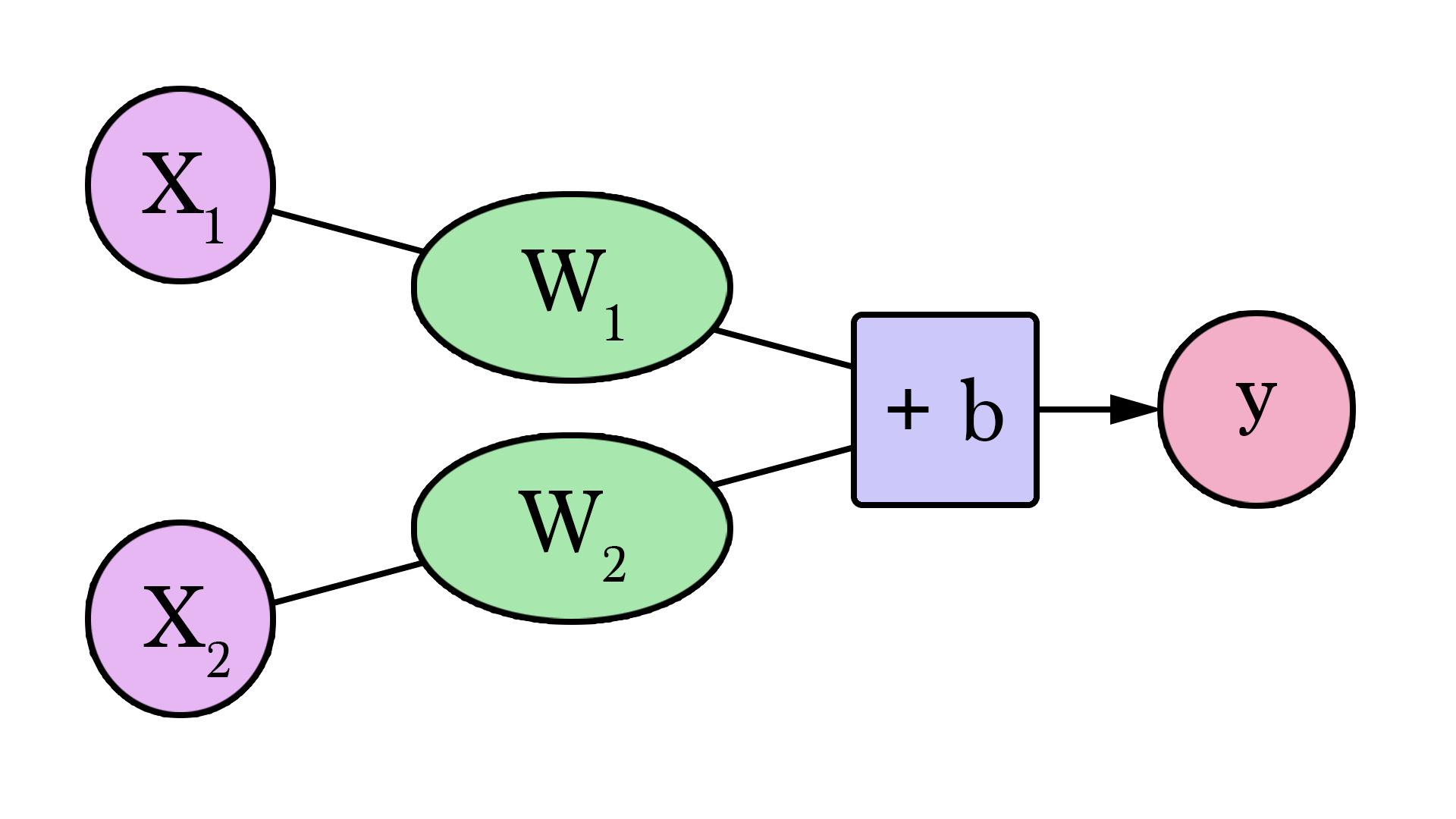
The NumPy package is the workhorse of data analysis, machine learning, and scientific computing in the python ecosystem. It vastly simplifies manipulating and crunching vectors and matrices. Some of python’s leading package rely on NumPy as a fundamental piece of their infrastructure (examples include scikit-learn, SciPy, pandas, and tensorflow). Beyond the ability to slice and dice numeric data, mastering numpy will give you an edge when dealing and debugging with advanced usecases in these libraries.
In this post, we’ll look at some of the main ways to use NumPy and how it can represent different types of data (tables, images, text…etc) before we can serve them to machine learning models.
In this video, I introduced word embeddings and the word2vec algorithm. I then proceeded to discuss how the word2vec algorithm is used to create recommendation engines in companies like Airbnb and Alibaba. I close by glancing at real-world consequences of popular recommendation systems like those of YouTube and Facebook.
My Illustrated Word2vec post used and built on the materials I created for this talk (but didn’t include anything on the recommender application of word2vec). This was my first talk at a technical conference and I spent quite a bit of time preparing for it. In the six weeks prior to the conference I spent about 100 hours working on the presentation and ended up with 200 slides. It was an interesting balancing act of trying to make it introductory but not shallow, suitable for senior engineers and architects yet not necessarily ones who have machine learning experience.
“There is in all things a pattern that is part of our universe. It has symmetry, elegance, and grace - those qualities you find always in that which the true artist captures. You can find it in the turning of the seasons, in the way sand trails along a ridge, in the branch clusters of the creosote
bush or the pattern of its leaves.
We try to copy these patterns in our lives and our society,
seeking the rhythms, the dances, the forms that comfort.
Yet, it is possible to see peril in the finding of
ultimate perfection. It is clear that the ultimate
pattern contains it own fixity. In such
perfection, all things move toward death.”
~ Dune (1965)
I find the concept of embeddings to be one of the most fascinating ideas in machine learning. If you’ve ever used Siri, Google Assistant, Alexa, Google Translate, or even smartphone keyboard with next-word prediction, then chances are you’ve benefitted from this idea that has become central to Natural Language Processing models. There has been quite a development over the last couple of decades in using embeddings for neural models (Recent developments include contextualized word embeddings leading to cutting-edge models like BERT and GPT2).
Word2vec is a method to efficiently create word embeddings and has been around since 2013. But in addition to its utility as a word-embedding method, some of its concepts have been shown to be effective in creating recommendation engines and making sense of sequential data even in commercial, non-language tasks. Companies like Airbnb, Alibaba, Spotify, and Anghami have all benefitted from carving out this brilliant piece of machinery from the world of NLP and using it in production to empower a new breed of recommendation engines.
In this post, we’ll go over the concept of embedding, and the mechanics of generating embeddings with word2vec. But let’s start with an example to get familiar with using vectors to represent things. Did you know that a list of five numbers (a vector) can represent so much about your personality?
2021 Update: I created this brief and highly accessible video intro to BERT
The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and sentences in a way that best captures underlying meanings and relationships is rapidly evolving. Moreover, the NLP community has been putting forward incredibly powerful components that you can freely download and use in your own models and pipelines (It’s been referred to as NLP’s ImageNet moment, referencing how years ago similar developments accelerated the development of machine learning in Computer Vision tasks).
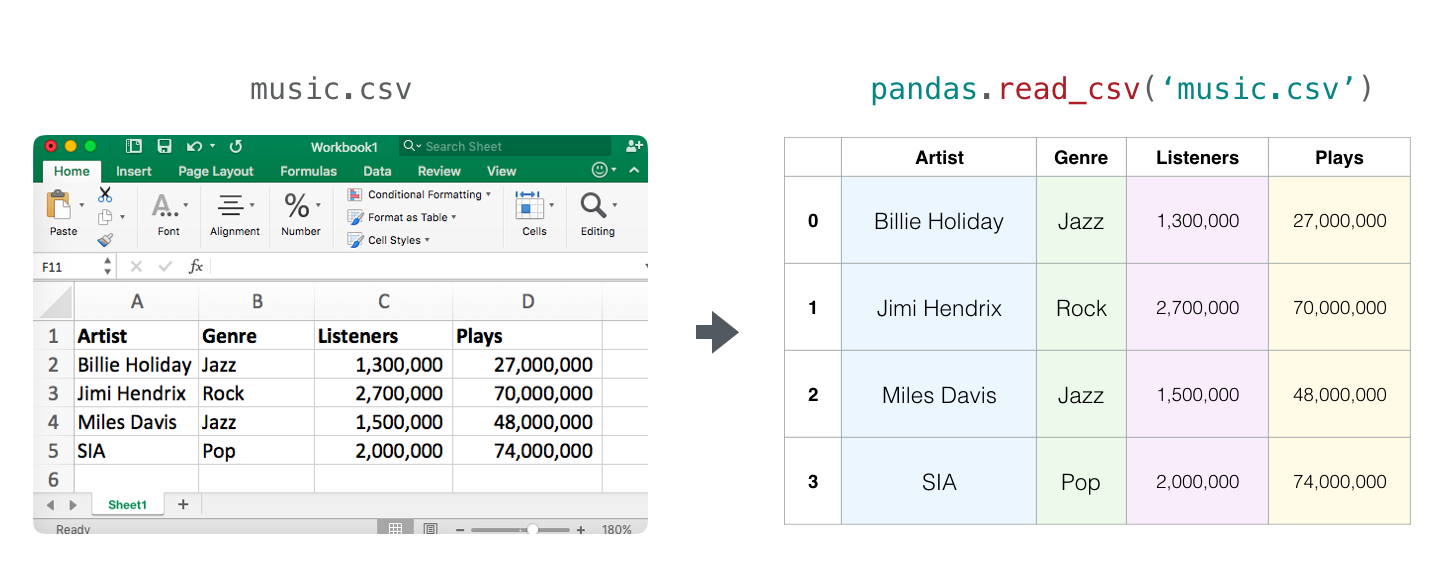
If you’re planning to learn data analysis, machine learning, or data science tools in python, you’re most likely going to be using the wonderful pandas library. Pandas is an open source library for data manipulation and analysis in python.
Loading Data
One of the easiest ways to think about that, is that you can load tables (and excel files) and then slice and dice them in multiple ways:
Update: This post has now become a book! Check out LLM-book.com which contains (Chapter 3) an updated and expanded version of this post speaking about the latest Transformer models and how they've evolved in the seven years since the original Transformer (like Multi-Query Attention and RoPE Positional embeddings).
In the previous post, we looked at Attention – a ubiquitous method in modern deep learning models. Attention is a concept that helped improve the performance of neural machine translation applications. In this post, we will look at The Transformer – a model that uses attention to boost the speed with which these models can be trained. The Transformer outperforms the Google Neural Machine Translation model in specific tasks. The biggest benefit, however, comes from how The Transformer lends itself to parallelization. It is in fact Google Cloud’s recommendation to use The Transformer as a reference model to use their Cloud TPU offering. So let’s try to break the model apart and look at how it functions.
The Transformer was proposed in the paper Attention is All You Need. A TensorFlow implementation of it is available as a part of the Tensor2Tensor package. Harvard’s NLP group created a guide annotating the paper with PyTorch implementation. In this post, we will attempt to oversimplify things a bit and introduce the concepts one by one to hopefully make it easier to understand to people without in-depth knowledge of the subject matter.
2025 Update: We’ve built a free short course that brings the contents of this post up-to-date with animations:
A High-Level Look
Let’s begin by looking at the model as a single black box. In a machine translation application, it would take a sentence in one language, and output its translation in another.
May 25th update: New graphics (RNN animation, word embedding graph), color coding, elaborated on the final attention example.
Note: The animations below are videos. Touch or hover on them (if you’re using a mouse) to get play controls so you can pause if needed.
Sequence-to-sequence models are deep learning models that have achieved a lot of success in tasks like machine translation, text summarization, and image captioning. Google Translate started using such a model in production in late 2016. These models are explained in the two pioneering papers (Sutskever et al., 2014, Cho et al., 2014).
I found, however, that understanding the model well enough to implement it requires unraveling a series of concepts that build on top of each other. I thought that a bunch of these ideas would be more accessible if expressed visually. That’s what I aim to do in this post. You’ll need some previous understanding of deep learning to get through this post. I hope it can be a useful companion to reading the papers mentioned above (and the attention papers linked later in the post).
A sequence-to-sequence model is a model that takes a sequence of items (words, letters, features of an images…etc) and outputs another sequence of items. A trained model would work like this:
I love using python’s Pandas package for data analysis. The 10 Minutes to pandas is a great place to start learning how to use it for data analysis.
Things get a lot more interesting once you’re comfortable with the fundamentals and start with Reshaping and Pivot Tables. That guide shows some of the more interesting functions of reshaping data. Below are some visualizations to go along with the Pandas reshaping guide.
I’m not a machine learning expert. I’m a software engineer by training and I’ve had little interaction with AI. I had always wanted to delve deeper into machine learning, but never really found my “in”. That’s why when Google open sourced TensorFlow in November 2015, I got super excited and knew it was time to jump in and start the learning journey. Not to sound dramatic, but to me, it actually felt kind of like Prometheus handing down fire to mankind from the Mount Olympus of machine learning. In the back of my head was the idea that the entire field of Big Data and technologies like Hadoop were vastly accelerated when Google researchers released their Map Reduce paper. This time it’s not a paper – it’s the actual software they use internally after years and years of evolution.
So I started learning what I can about the basics of the topic, and saw the need for gentler resources for people with no experience in the field. This is my attempt at that.
In November 2015, Google announced and open sourced TensorFlow, its latest and greatest machine learning library. This is a big deal for three reasons:
Machine Learning expertise: Google is a dominant force in machine learning. Its prominence in search owes a lot to the strides it achieved in machine learning.
Scalability: the announcement noted that TensorFlow was initially designed for internal use and that it’s already in production for some live product features.
Ability to run on Mobile.
This last reason is the operating reason for this post since we’ll be focusing on Android. If you examine the tensorflow repo on GitHub, you’ll find a little tensorflow/examples/android directory. I’ll try to shed some light on the Android TensorFlow example and some of the things going on under the hood.